Generated samples with 4k resolution
We expand the given local image upwards and downwards twice, and left and right a total of 16 times, to follow the given global caption.
The resolution of the generated image is 4608 X 1536.
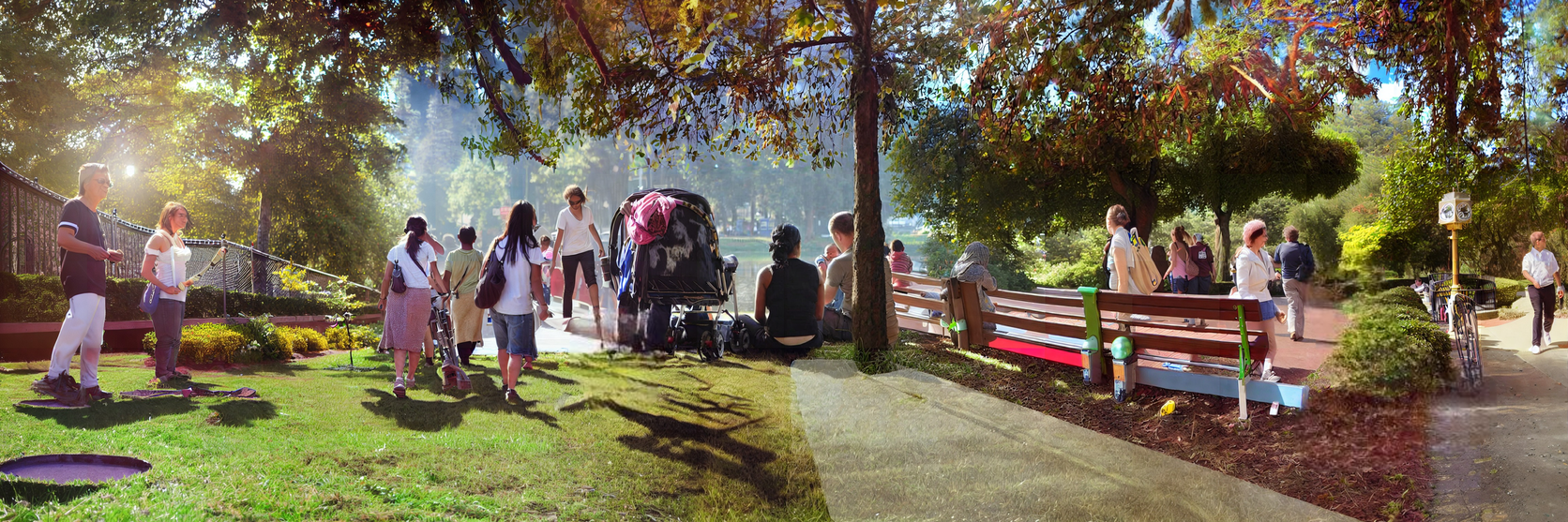
A bustling park scene unfolds with sunlight filtering through trees, where on one side, people pull bicycles on lush green grass, and on the other, families and friends take leisurely walks or sit by a tranquil lake, immersing themselves in the peaceful harmony of nature's embrace.

A view unfolds with horse-drawn carriages winding along a path bordered by vibrant flowers and a grand clock tower overseeing the tranquil botanical setting.

A vibrant scene of water sports on a scenic lake, featuring a variety of boats, expert wakeboarders, and adventurous waterskiers. The tranquil environment is enriched by lush greenery and picturesque buildings, forming an dynamic landscape.
Abstract
Text-guided image editing and generation methods have diverse real-world applications. However, text-guided infinite image synthesis faces several challenges. First, there is a lack of text-image paired datasets with high-resolution and contextual diversity. Second, expanding images based on text requires global coherence and rich local context understanding. Previous studies have mainly focused on limited categories, such as natural landscapes, and also required to train on high-resolution images with paired text. To address these challenges, we propose a novel approach utilizing Large Language Models (LLMs) for both global coherence and local context understanding, without any high-resolution text-image paired training dataset. We train the diffusion model to expand an image conditioned on global and local captions generated from the LLM and visual feature. At the inference stage, given an image and a global caption, we use the LLM to generate a next local caption to expand the input image. Then, we expand the image using the global caption, generated local caption and the visual feature to consider global consistency and spatial local context. In experiments, our model outperforms the baselines both quantitatively and qualitatively. Furthermore, our model demonstrates the capability of text-guided arbitrary-sized image generation in zero-shot manner with LLM guidance.
Method Overview
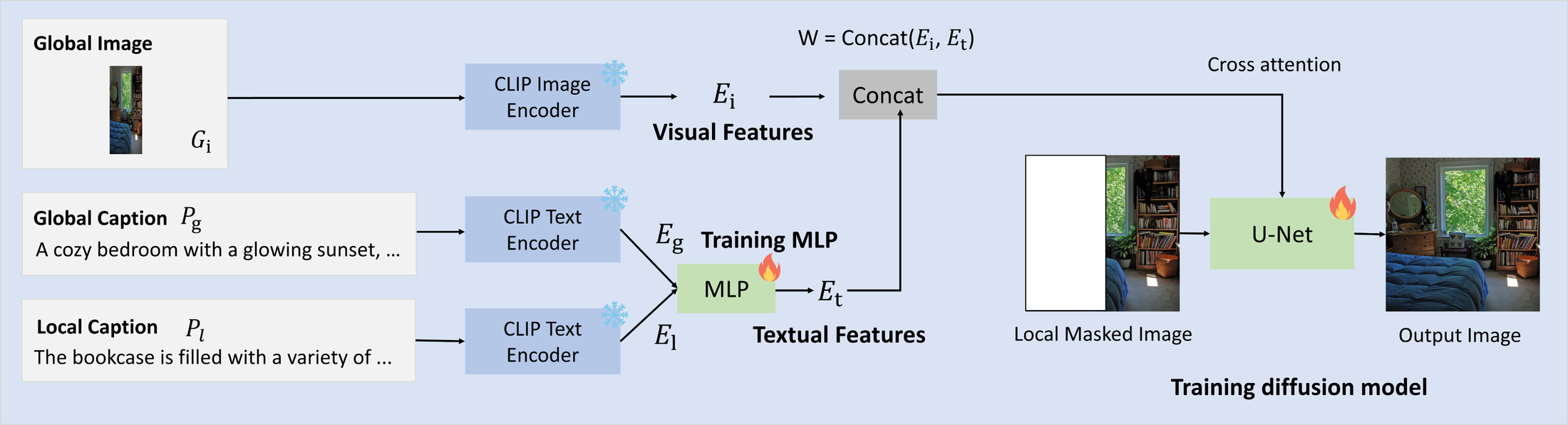
Model Architecture. We fine-tune the diffusion model using local masked image as input, conditioned on the $W$ vector. Green boxes are trainable networks. Blue boxes are frozen networks.
Generated Image Results
We expand the image eight times. The expanded image has a resolution of 2560 X 512 or 512 X 2560.

A cozy and elegantly decorated living room featuring a comfortable sofa, a fireplace, and large windows.

A little girl is sitting on a bed next to a lamp in a bedroom that opens to a garden.

A garden pathway featuring vibrant greenery and blooming flowers, with a motorcycle parked.

A vibrant view of a bustling marina nestled in a lush green valley, showing boats with a serene promenade and flower beds under a clear blue sky.

A sunny day in the park captures the joy of childhood with children engaging in outdoor activities, their laughter and playfulness creating a lively atmosphere.

A well-organized kitchen scene with open shelving full of utensils and dishes, featuring a woman in a patterned dress engrossed in cooking, a sign of daily life and warmth.

A view of a city street captures a stop sign, a parking meter, and the sleek lines of a modern sidewalk with architectures.

Vivid paper roses cascade from a vase, adding a splash of color above a crafting table laden with fabric and laces.

A tennis player serving the ball, with the audience in the background, at a professional tennis match.

A sun-soaked beachfront with a modern cityscape, where waters shadowed by towering buildings.

A child is engrossed in a video game, surrounded by cozy blankets and a cat resting nearby.

Giraffes, zebras and elephants freely roam in the savannah.
Acknowledgment
This work was supported by Institute of Information \& communications Technology Planning \& Evaluation (IITP) grant funded by the Korea government (MSIT) (No.2022-0-00608, Artificial intelligence research about multi-modal interactions for empathetic conversations with humans \& No.RS-2020-II201336, Artificial Intelligence graduate school support(UNIST)) and the National Research Foundation of Korea(NRF) grant funded by the Korea government(MSIT) (No. RS-2023-00219959).